Nvidia_Mellanox_CX5和6DX系列网卡_RDMA_RoCE_无损和有损_DCQCN拥塞控制等技术简介-一文入门RDMA和RoCE有损无损
Nvidia_Mellanox_CX5和6DX系列网卡_RDMA_RoCE_无损和有损_DCQCN拥塞控制等技术简介-一文入门RDMA和RoCE有损无损
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和 《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Nvidia_Mellanox_CX5和6DX系列网卡_RDMA_RoCE_无损和有损_DCQCN拥塞控制等技术简介-一文入门RDMA和RoCE有损无损
ECN: 显式拥塞通知 (Explicit Congestion Notification) 是互联网协议和传输控制协议的扩展,在 RFC 3168 (2001) 中定义。 ECN 允许在不丢失数据包的情况下进行网络拥塞的端到端通知。 ECN 是一项可选功能,当底层网络基础设施也支持时,可以在两个启用 ECN 的端点之间使用
DSCP(differentiated services code point): 差分服务代码点, 差分服务或 DiffServ 是一种计算机网络体系结构,它指定了一种在现代 IP 网络上分类和管理网络流量并提供服务质量 (QoS) 的机制。 例如,DiffServ 可用于为语音或流媒体等关键网络流量提供低延迟,同时为 Web 流量或文件传输等非关键服务提供尽力而为的服务。DiffServ 在 IP 标头的 8 位差分服务字段(DS 字段)中使用 6 位差分服务代码点 (DSCP),用于数据包分类。 DS 字段取代了过时的 IPv4 TOS 字段
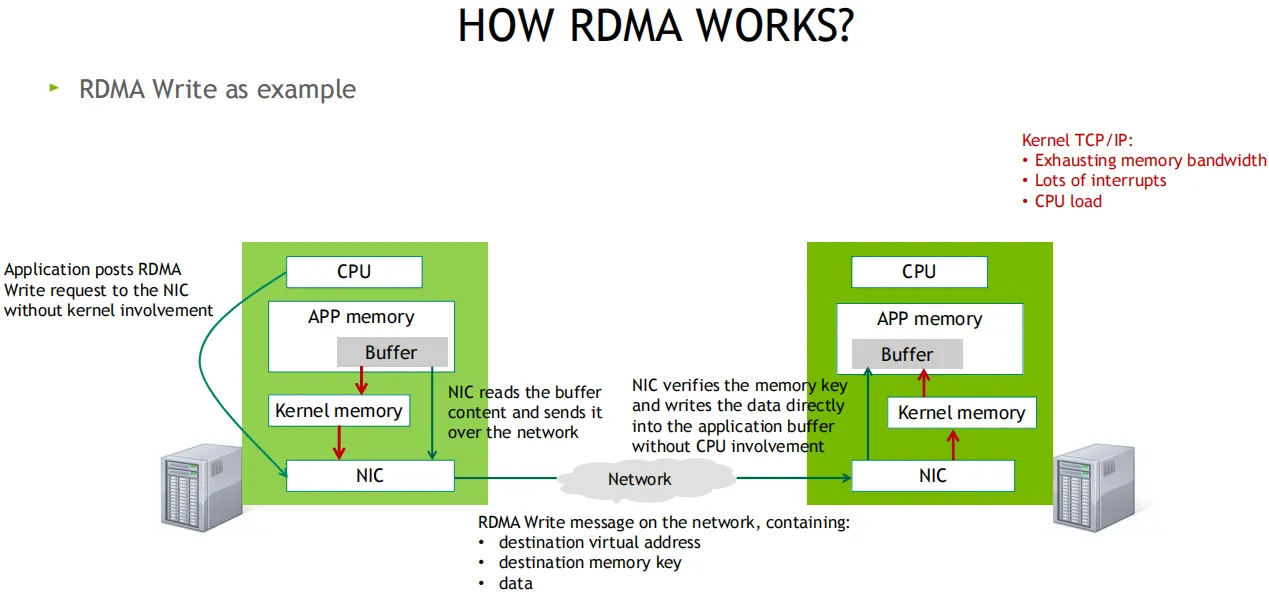
发送端CPU准备好发送数据后会敲一次门铃, 而接收方收到网卡数据后不会通知CPU(降低开销)
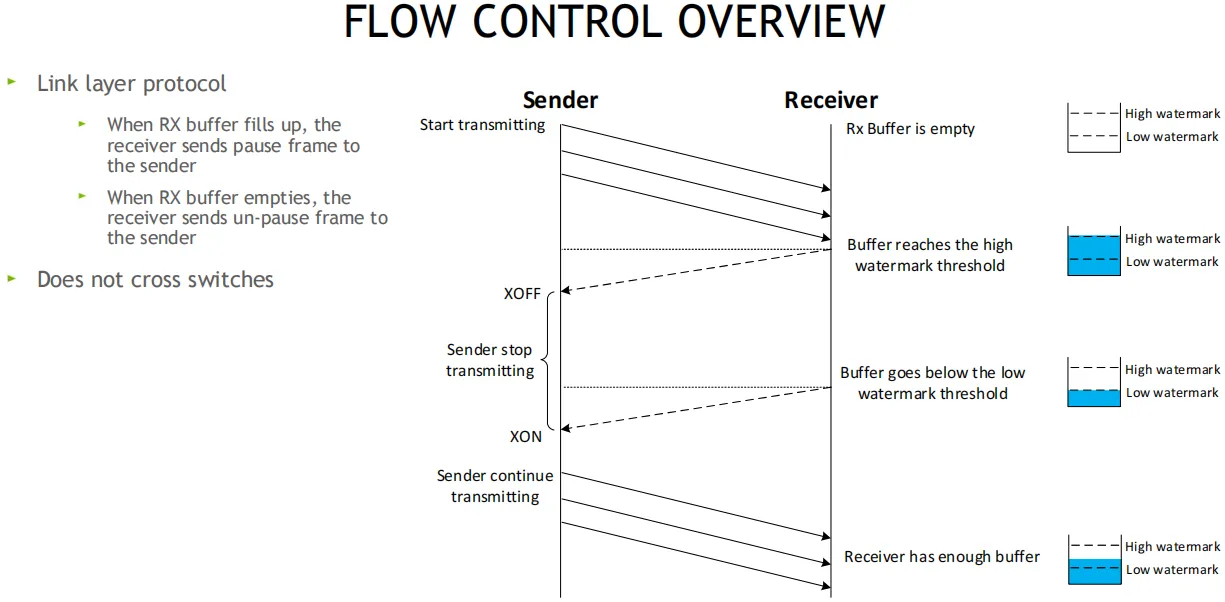
流控为链路层协议, 在接收方的RX Buffer接收缓存区设置高和低水位, 接收方Buffer填满时, 发送暂停帧Pause给发送方, 发送方XOFF, 并暂停发包, 等接收方释放出接收Buffer后, 给发送方发送一个UN-Pause帧, 发送方XON, 重新开始发送, 该方案不会跨越交换机
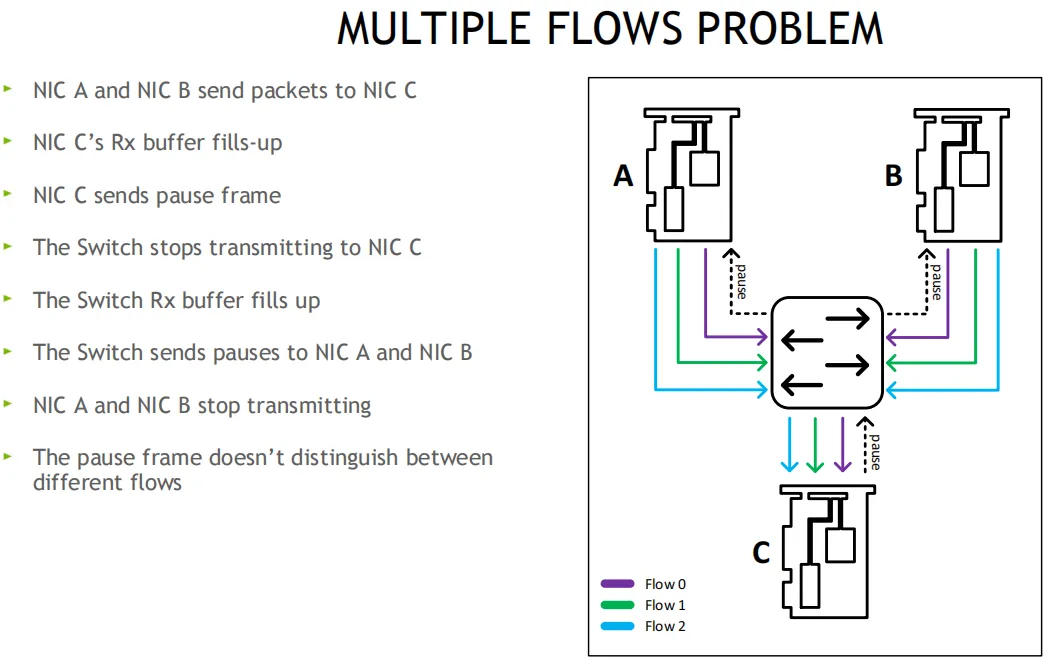
解决: 无损方案, PFC优先级流控, 用8个优先级(0-7), 独立控制每个流分类服务CoS, 网卡可将Buffer切分, 比如一半启动无损, 一半保持有损
主机侧: 可通过ethtool, mlnx_qos工具查看和配置PFC流控, 交换机侧也需要做对应的配置, 如果是跨机房,也需要保持类似的配置(无损痛点之一, 有时候交换机不在咱们得控制范围, 所以这种规模的网络, 限制了无损的配置)

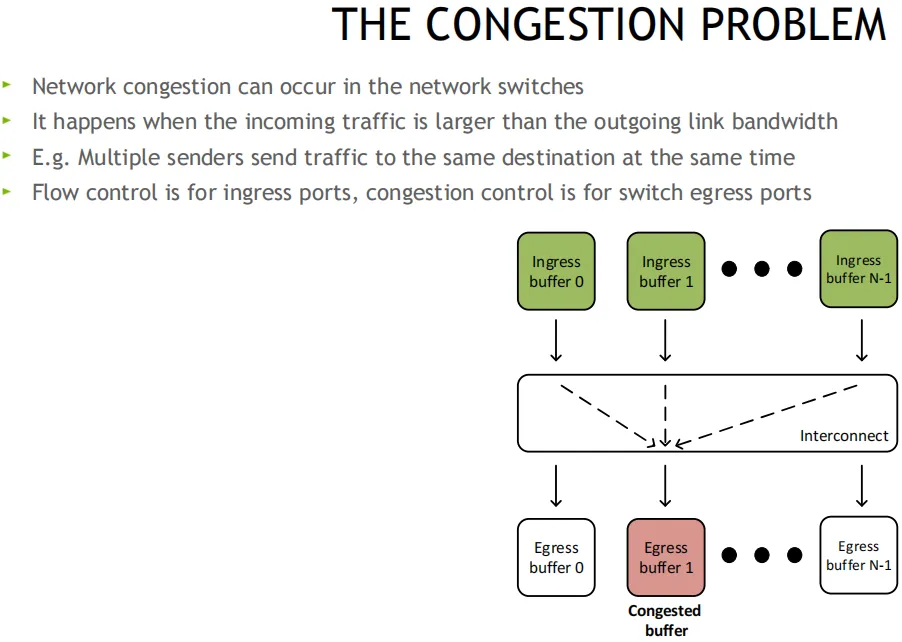
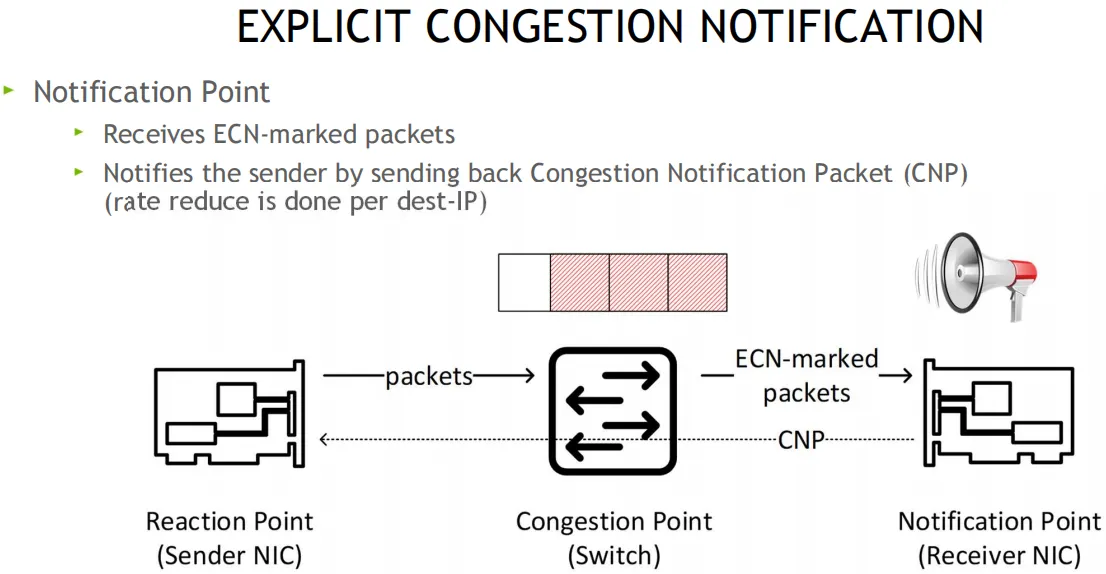
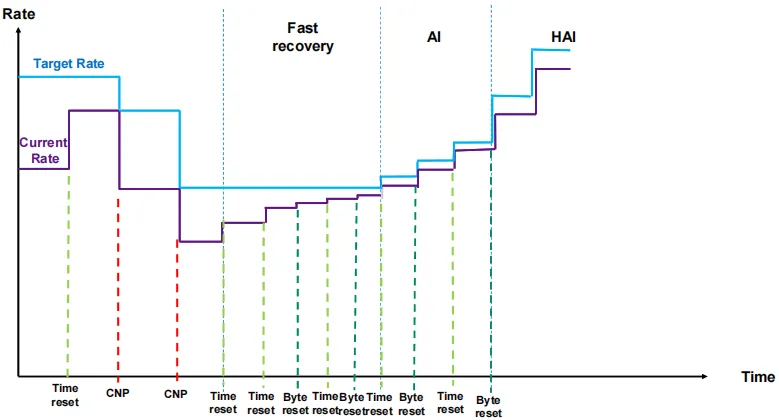
原理: 当交换机检测到拥塞时, 将出口包打上ECN标记, 接收端收到ECN包后, 因为有发送端的QP信息, 发送拥塞通知包CNP给发送端, 这时候假如发送端收到多个接收端发来的ECN包, 发送方需要有一个分布式拥塞控制算法(DCQCN, 由Mellanox和微软共同开发), 来降速和调度发送, 一段时间发端没有收到CNP时, 这个时候需要恢复流量, 目前是按照三个阶段来恢复, 快速恢复FR(fast recovery) - 二分递增AI(additive increase) - 更快增加HAI(hyper increase)
在cx6 DX网卡上可自定义拥塞控制算法, 比如阿里和google都有自己的拥塞管理算法, 算法参考:
一键配置: 可通过脚本检测和配置, 用于管理 RoCE 部署的系统高性能网络接口配置的命令行实用程序, 参考:
接收方发送一个OOS_NACK(乱序包, 消极应答)和CNP, 发送方收到CNP后, 计数器再加1, 并降低速率
随着人工智能(AI)的迅速发展,越来越多的应用需要巨大的GPU计算资源。GPUDirect RDMA 是 Kepler 级 GPU 和 CUDA 5.0 中引入的一项技术,可以让使用pcie标准的gpu和第三方设备进行直接的数据交换,而不涉及CPU。
在高性能计算和深度学习领域,GPU已成为关键工具。然而,随着模型复杂度和数据量的增加,单个GPU难以满足需求,多GPU甚至多服务器协同工作成为常态。本文探讨了三种主要的GPU通信互联技术:GPUDirect、NVLink和RDMA。GPUDirect通过绕过CPU实现GPU与设备直接通信;NVLink提供高速点对点连接和支持内存共享;RDMA则在网络层面实现直接内存访问,降低延迟。这些技术各有优势,适用于不同场景,为AI和高性能计算提供了强大支持。
带你读《弹性计算技术指导及场景应用》——2. 技术改变AI发展:RDMA能优化吗?GDR性能提升方案
带你读《弹性计算技术指导及场景应用》——2. 技术改变AI发展:RDMA能优化吗?GDR性能提升方案
弹性RDMA(Elastic Remote Direct Memory Access,简称eRDMA),是阿里云自研的云上弹性RDMA网络,底层链路复用VPC网络,采用全栈自研的拥塞控制CC(Congestion Control )算法,兼具传统RDMA网络高吞吐、低延迟特性,同时支持秒级的大规模RDMA组网。基于弹性RDMA,开发者可以将HPC应用软件部署在云上,获取成本更低、弹性更好的高性能应用集群;也可以将VPC网络替换成弹性RDMA网络,加速应用性能。
阿里云徐成:CIPU最新秘密武器-弹性RDMA的技术解析与实践|阿里云弹性计算技术公开课直播预告
弹性RDMA(Elastic Remote Direct Memory Access,简称eRDMA),是阿里云自研的云上弹性RDMA网络,底层链路复用VPC网络,采用全栈自研的拥塞控制CC(Congestion Control )算法,兼具传统RDMA网络高吞吐、低延迟特性,同时支持秒级的大规模RDMA组网。基于弹性RDMA,开发者可以将HPC应用软件部署在云上,获取成本更低、弹性更好的高性能应用集群;也可以将VPC网络替换成弹性RDMA网络,加速应用性能。
本篇以 first contact (通信两端建立首个连接) 场景为例,介绍 SMC-R 通信流程。
目录 浅析GPU通信技术(上)-GPUDirect P2P 浅析GPU通信技术(中)-NVLink 浅析GPU通信技术(下)-GPUDirect RDMA 1. 背景 前两篇文章我们介绍的GPUDirect P2P和NVLink技术可以大大提升GPU服务器单机的GPU通信性...
PolarDB-SCC使用问题之为什么PolarDB-SCC选择使用基于RDMA的日志传输
带你读《弹性计算技术指导及场景应用》——2. 技术改变AI发展:RDMA能优化吗?GDR性能提升方案
阿里云徐成:CIPU最新秘密武器-弹性RDMA的技术解析与实践|阿里云弹性计算技术公开课直播预告






